Multizone Sound Reproduction
The independent synthesis of individual acoustic scenes in different regions of a reproduction room is a topic that has attracted a lot of attention in recent years. At the LMS, the research activities in this field started in 2012, where the well-known pressure matching approach was extended by simultaneously optimizing the sound pressure and the particle velocity vector. Inspired by the Kirchhoff-Helmholtz integral equation, the developed Joint Pressure and Velocity Matching (JPVM) technique aims at controlling the sound field on closed contours around the individual listening areas. As a result, no control points/microphones are required in the interior of the listening areas, but merely on their surrounding contours.
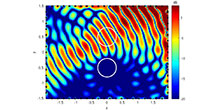
An exemplary sound field synthesized with JPVM is illustrated in Fig. 1, where the two local listening areas are indicated by white circles. In the upper area, a plane wave front originating from direction 30° is synthesized, while the energy in the lower area is minimized.
Not only has the JPVM algorithm been investigated using simulations, but an adaptive real-time demonstration system has also been implemented in the audio lab of the LMS. Together with a video-based face detection and tracking system, it allows for constantly focusing the acoustic energy to the current listeners’ positions. Furthermore, the impact of reverberation and inevitable imperfections (such as positioning errors of the loudspeakers, copy-to-copy variations of their properties as well as their directivity) on the reproduction performance has been investigated.
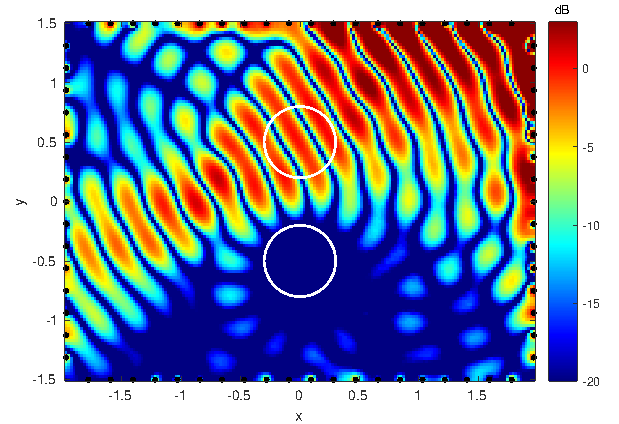
Figure 1: Example of a sound field as obtained with the JPVM approach, where the two local listening areas are indicated by white circles. In the upper area, a plane wave front originating from 30° is synthesized, while the acoustic energy in the lower area is minimized.
Binaural Rendering
The idea of binaural rendering is to evoke certain Interaural Time Differences (ITDs) and Interaural Level Differences (ILDs) at the listener’s ears such that a (virtual) sound source is perceived without the existence of a physical sound source. ILDs stem from the fact that the sound waves arriving at the contralateral side of the head are attenuated due to head shadowing effects. Similarly, ITDs arise if the propagation paths from the sound source to the two ears have different lengths, as illustrated in Fig. 1. These two parameters are determined by the source position, and they are the most important spatial cues for the human hearing when it comes to the localization of sound sources in the horizontal plane. On the other hand, they can be used to “trick” the human hearing and pretend the existence of a sound source. In the simplest case, this can be done with the help of headphones, where the sound field at the ears can be easily controlled. However, as headphones isolate the listener from the environment and may be uncomfortable when wearing them for a long time, it is desirable to perform binaural rendering via distant loudspeakers. This is done with a concept referred to as Cross-Talk Cancellation (CTC), which is an inverse filtering technique and is equivalent to a set of two beamformers, each of which focusses the sound waves towards one ear and has a spatial null at the respective other ear. Such systems are preferably installed in a low reverberant environment, as undesired room reflections may strongly degrade the reproduction performance and, thus, need to be compensated if they are too dominant.
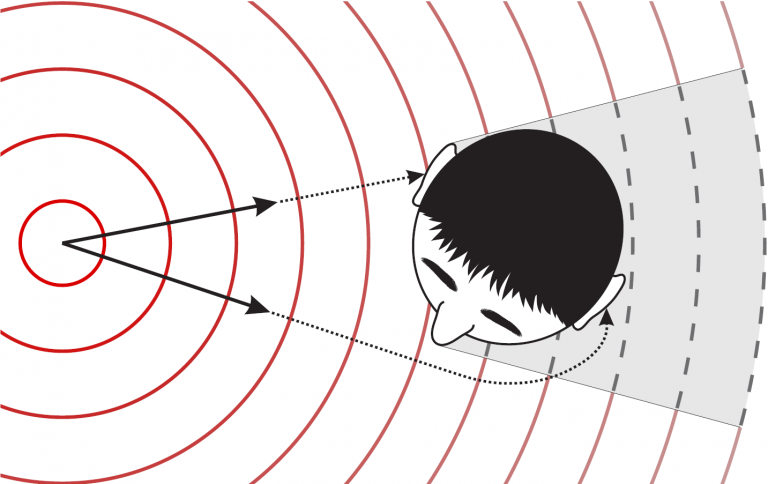
Figure 1: Illustration of Interaural Time Differences (ITDs) and Interaural Level Differences (ILDs).
Wave-field Synthesis
Recently emerging techniques like wave field synthesis (WFS) or higher-order Ambisonics (HOA) allow for a spatial audio reproduction beyond the capabilities of the wide-spread 5.1 or 7.1 systems which can only achieve an optimal reproduction at a single position, the so-called sweet spot. A crucial property of WFS is that the listener may move freely within a spatially extended listening area, experiencing a natural perception of the reproduced scene from different positions. This enables the listener to virtually attend an acoustic scene, rather than to perceive only a limited set of spatial key features, which would be provided by conventional systems. Although achieving this was the first step towards immersive audio environments, there are various challenges to master in order to achieve a truly immersive user experience.
Often, it is desired to use reproduction techniques like WFS or HOA for communication applications. Examples are speech-driven human-machine interfaces for gaming or simulation environments, but also high-quality telepresence systems (as illustrated in Figure 1). In any of these scenarios, at least one, but most likely many microphones are used to record the local acoustic scene, possibly while another acoustic scene is simultaneously reproduced by the loudspeakers. In the latter case, the microphone signals describe a superposition of the local acoustic scene and the echoes of the loudspeaker signals. As the latter would annoy the far-end party in a teleconference or significantly deteriorate the performance of an automated speech recognition system, they have to be removed, e.g., by means of acoustic echo cancellation. While this problem is mostly solved for systems with a low number of loudspeaker channels, handling a large number of loudspeaker channels remains challenging due to the computational and algorithmic complexity.
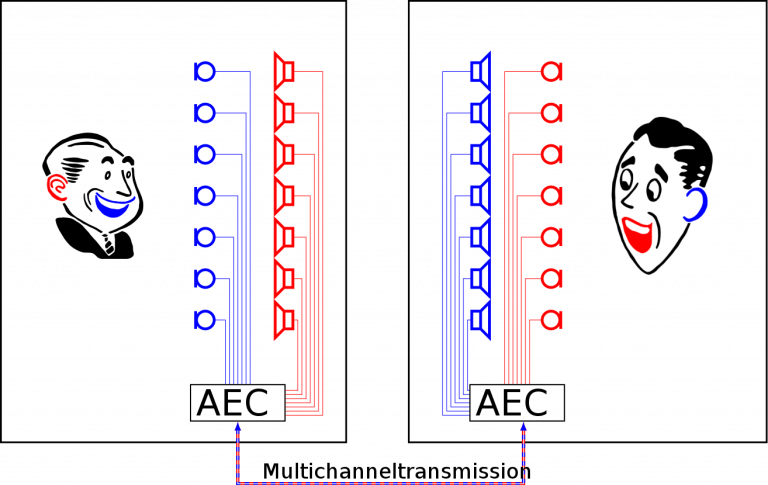
Figure 1: Multichannel teleconference scenario.
Listening Room Equalization
A weakness of WFS is the relatively strict requirement for the listening room. The wall must be acoustically treated to avoid acoustic reflections by the walls, which is expensive and very difficult for some surfaces as, e.g., windows. As WFS requires a loudspeaker setup which already provides a highly-detailed control over the reproduced wave field, the capabilities of the loudspeaker array may be exploited to compensate for those undesired room properties. Locating an additional microphone array in the listening room, the actually reproduced wave field may be measured a pre-equalization filters for the loudspeaker signals may be determined. As the room temperature or the audience attendance in the room may vary over time, this has to be facilitated by adaptive filters.
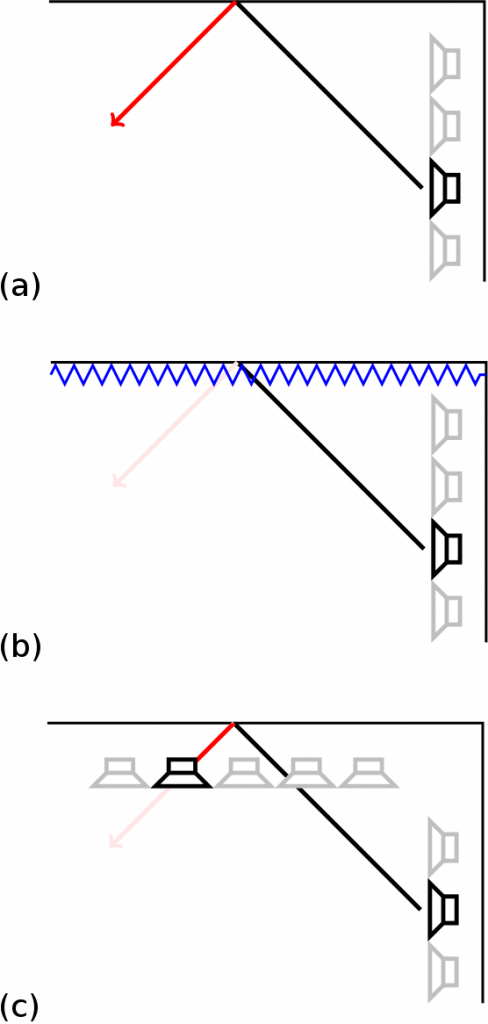
Figure 1: Listening room equalization: (a) room with reflective walls, (b) room with absorbing walls, (c) active listening room equalization