Our group works on different topics in the domain of image and video compression. In this direction, we study state-of-the-art coding standards like HEVC and we develop new methods for upcoming standards like VVC. In addition, we tackle new and unconventional approaches for coding content like medical images videos, fisheye videos, or 360°-videos.
Coding with Machine Learning
Video Coding for Deep Learning-Based Machine-to-Machine Communication
| Contact |
| Marc Windsheimer, M.Sc. |
| E-Mail: marc.windsheimer@fau.de |
| Link to person |
Commonly, video codecs are designed and optimized for humans as final user. Nowadays, more and more multimedia data is transmitted for so-called machine-to-machine (M2M) applications, which means that the data is not observed by humans as the final user but successive algorithms solving several tasks. These tasks include smart industry, video surveillance, and autonomous driving scenarios. For these M2M applications, the detection rate of the successive algorithm is decisive instead of the subjective visual quality for humans. In order to evaluate the coding quality for M2M applications, we are currently focusing on neural object detection with Region-based Convolutional Neural Networks (R-CNNs).

One interesting question regarding the problem of video compression for M2M communication systems is how much the original data can be compressed until the detection rate drops. Besides, we are testing modifications on current video codecs to achieve an optimal proportion of compression and detection rate.
Deep Learning for Video Coding
Learning-based components embedded into hybrid video coding frameworks
| Contact |
| Simon Deniffel, M.Sc. |
| E-Mail: fabian.brand@fau.de |
| Link to person. |
| PD Dr.-Ing. habil. Jürgen Seiler |
| E-Mail: juergen.seiler@fau.de |
| Link to person. |
The use of neural networks greatly increases the flexibility of video comperssion, since the underlying statistics and probability distributions can be directly learned from the data. In contrast, traditional video coders rely on hand-crafted transforms and statistics. The main topic of this research is the application of so-called conditional inter frame coders. This approach solves the problem of predicted transmission of a video frame. To exploit temporal redundancy, the coder uses a prediction signal which was generated from a previous frame. Traditionally, this prediction is subtracted from the current frame and the difference is transmitted subsequently before being added the prediction signal again on the decoder side. Using information theory, however, it can be shown that this method is not optimal. It is better to transmit the current frame under the condition of knowing the prediction. Such a conditional coder is infeasible with traditional methods. Neural networks on the other hand are able to directly learn the corresponding statistics.
We reasearch the theoretical and practical properties of a conditional inter frame coder. The focus lies on the description, modeling and alleviation of so-called information bottlenecks, which can occur in coditional coders and may reduce the achievable compression efficiency.
Residual Coder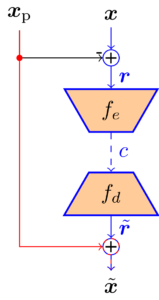 |
Conditional Coder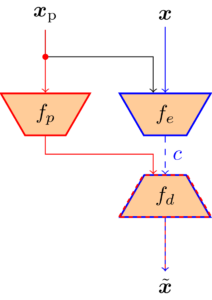 |
End-to-end optimized image and video compression
| Contact |
| Anna Meyer, M.Sc. |
| E-Mail: anna.meyer@fau.de |
| Link to person |
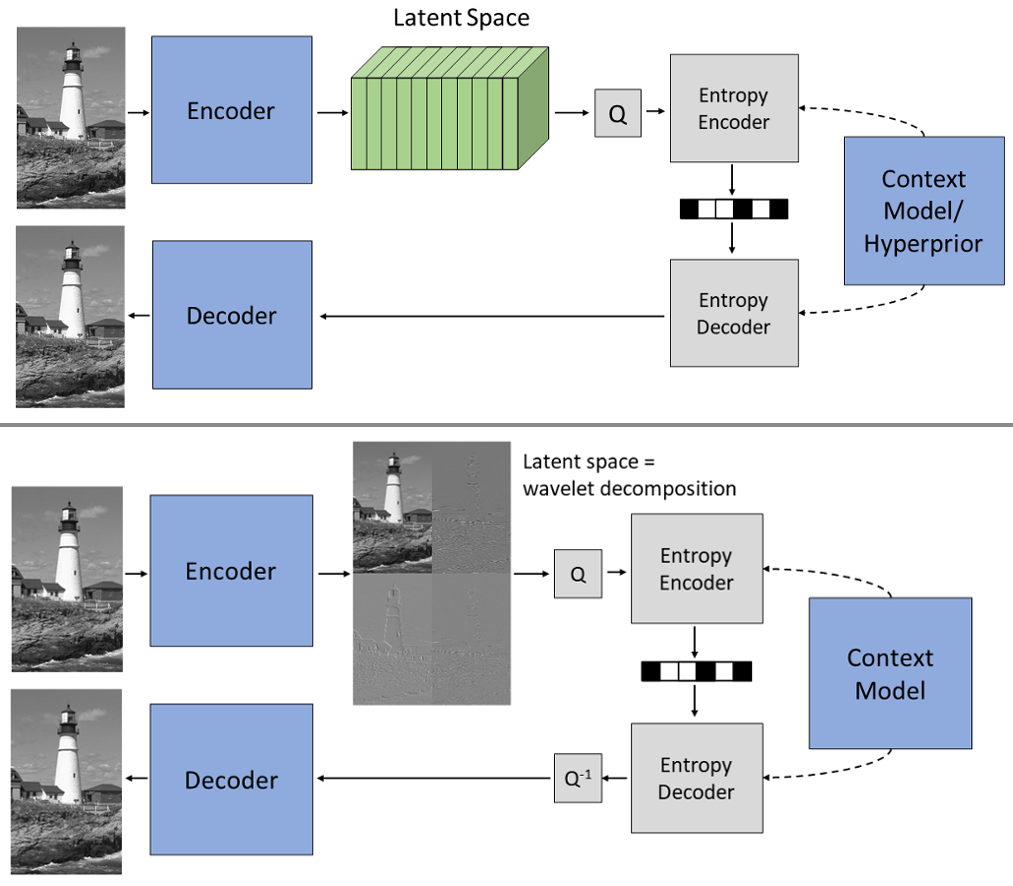
Recently, different components of video coders have been successfully improved using neural networks. However, these approaches still rely on separately designed and optimized modules. End-to-end optimized image and video compression is an emerging field that allows optimizing the entire coding framework jointly. The most popular approaches are based on compressive autoencoders: The encoder computes a latent representation that is subsequently quantized and losslessly entropy coded. Next, the decoder computes the reconstructed image or video based on the quantized latent representation.
It has been shown that the latent space contains redundant information that can be reduced by, e.g., a spatial context model or channel conditioning. Exploiting possible remaining redundancies is challenging due to the lack of interpretability of the latent space. An interesting approach is thus designing encoder and decoder according to the lifting scheme, which results in a latent space that represents a learned wavelet decomposition. This knowledge about the structure of the latent space facilitates the development of efficient learning-based methods for image and video compression. In addition, approaches from classical wavelet compression can be adopted.
Energy and Power Efficient Video Communications
Nowadays, video communications have conquered the mass markets such that billions of end-users worldwide make use of online video applications on highly versatile devices like smartphones, TVs, or tablet PCs. Recent studies show that 1% of the greenhouse gas emissions worldwide are related to video communication services (link). This number includes all factors in the video communication toolchain such as video capture, compression, storage, transmission, decoding, and replay. Due to the large impact and the potential rise in video communication demand in the future, it is highly important to investigate the energy efficiency of practical solutions and come up with new ideas to allow a sustainable use of this technology.
![]()
To tackle this important problem, our group is committed to perform research in the field of energy efficient video communication solutions. In the past, we constructed dedicated measurement setups to be able to analyze the energy and the power consumption of various hardware and software tools being related to video communications. In terms of hardware, we tested desktop PCs, evaluation boards, smartphones, and distinct components of these devices. In terms of software, we investigated various decoders for multiple compression standards, hardware chips, and fully-functional media players. With the help of this data, we were able to develop accurate energy and power models describing the consumption in high detail. Additionally, these models allowed us to come up with new ideas to reduce and optimize the energy consumption.
We strive to dig deeper into this topic to obtain a fundamental understanding of all components contributing to the overall power consumption. Current topics include the encoding process, streaming and transmission issues, and modern video formats like 360° video coding. For future work, we are always searching for interesting ideas and collaborations to contrive new and promising solutions for energy efficient video communications. We are happy if you are interested and support our work.
Currently, we are working on the following topics:
Energy Efficient Video Coding
| Contact |
| Matthias Kränzler, M.Sc. |
| E-Mail: matthias.kraenzler@fau.de |
| Link to person |
In recent years, the amount and share of video-data in the global internet data traffic has steadily increasing. Both the encoding on the transmitter side and the decoding on the receiver side have a high energy demand. Research on energy-efficient video decoding has shown that it is possible to optimize the energy demand of the decoding process. This research area deals with the modeling of the energy required for the encoding of compressed video data. The aim of the modeling is to optimize the energy efficiency of the entire video coding.
 „Big Buck Bunny“ by Big Buck Bunny is licensed under CC BY 3.0
„Big Buck Bunny“ by Big Buck Bunny is licensed under CC BY 3.0
Energy Efficient Video Decoding
| Contact |
| Geetha Ramasubbu, M.Sc. |
| E-Mail: geetha.ramasubbu@fau.de |
| Link to person |
This field of research tackles the power consumption of video decoding systems. In this respect, software as well as hardware systems are studied in high detail. An detailed analysis of the decoding energy on various platforms with various conditions can be found on the DEVISTO homepage:
Decoding Energy Visualization Tool (DEVISTO)
With the help of a high number of measurements, sophisticated energy models could be constructed which are able to accurately estimate the overall power and energy. A visualization of the modeling process for software decoding is given on the DENESTO homepage:
Decoding Energy Estimation Tool (DENESTO)

Finally, the information from the model can be exploited in rate-distortion optimization during encoding to obtain bit streams requiring less decoding energy. The source code of such an encoder can be downloaded here:
Decoding-Energy-Rate-Distortion Optimization for Video Coding (DERDO)
Energy-efficient Video Encoding
| Contact |
| Geetha Ramasubbu., M.Sc. |
| E-Mail: geetha.ramasubbu@fau.de |
| Link to person |
The research on energy consumption is useful and relevant for several reasons. Firstly, we use many portable devices, such as smartphones, or tablet PCs, to record, store, and upload videos to the Internet or streaming. A necessary step here is to compress the videos, which have a significant energy requirement and limit the battery of portable devices. Secondly, the total energy consumption of today’s coding systems is globally significant. Most video-based social networking services often use huge server farms to encode and transcode, which causes related costs due to their energy consumption. Therefore, it is beneficial for practical applications if the encoding process requires little electrical energy, as this can extend the battery life of portable devices and reduce energy consumption costs.
Furthermore, video IP traffic has increased significantly in recent years and is expected to be 82% by 2022. In addition, the compression methods used for encoding have evolved considerably in recent years. As a result, not only do the modern codecs provide a greater number of compression methods, but their processing complexity has also greatly increased, leading to a significant increase in the energy demand on the transmitter side. Therefore, research on energy-efficient video encoding is critical and globally significant. This research deals with measuring and modeling the energy consumption of various encoder systems. The encoding energy modeling aims to obtain an energy estimate of the encoding process and identify the energy-demanding encoding sub-processes.
Coding of ultra wide-angle and 360° video data
Projection-based video coding
| Contact |
| Andy Regensky, M.Sc. |
| E-Mail: andy.regensky@fau.de |
| Link to person |
Ultra-wide angle and 360° video data is subject to a variety of distortions that do not occur in conventional video data recorded with perspective lenses. These distortions occur mainly because ultra wide-angle lenses do not follow the pinhole camera model and therefore have special image characteristics. This becomes clear, for example, as straight lines are displayed in a curved form on the image sensor. This is the only way to achieve fields of view of 180° and more with only one camera. By means of so-called stitching processes, several camera views can be combined to form 360° video, which allow a complete all-round view. Often this is achieved by using two ultra wide-angle cameras, each camera capturing a hemisphere. To be able to compress the resulting spherical 360° recordings using existing video codecs, the images must be projected onto the two dimensional image surface. Various mapping functions are used for this purpose. Often, the Equirectangular format is chosen, which is comparable to the representation of the globe on a world map, and thus depicts 360° in horizontal and 180° in vertical direction.
Since conventional video codecs are not adapted to mapping functions deviating from the perspective projection, losses occur which can be reduced by taking the actual projection formats into account. Therefore, in this project different coding aspects are investigated and optimized with respect to the occurring projections of ultra wide-angle and 360° video data. A special focus lies on projection-based motion compensation and intra-prediction.

Coding of screen content
Screen content coding based on machine learning and statistical modelling
| Contact |
| Hannah Och, M.Sc. |
| E-Mail: hannah.och@fau.de |
| Link to person |
In recent years processing of so-called screen content has increasingly attracted attention. Screen content represents images, which can typically be seen on desktop PCs, smartphones or similar devices. Such images or sequences have very diverse statistical properties. Generally, they contain ‘synthetic’ content, namely buttons, graphics, diagrams, symbols, texts, etc. which have two significant characteristics: small varieties of colors as well as repeating patterns. Next to aforesaid structures, screen content also includes ‘natural’ content, like photographs, videos, medical images or computer generated photo-realistic animations. Unlike synthetic content natural images are characterized by irregular color gradients and a certain amount of noise. Screen content is typically a mixture of both synthetic and natural parts. The transmission of such images and image sequences is required for a multitude of applications such as screen sharing, cloud computing and gaming.
However, screen content can be a challenge for conventional coding schemes, since they are mostly optimized for camera-captured (‘natural’) scenes and cannot compress screen content efficiently. Thus, this project focuses on the further development and performance measurement based on a novel compression method for lossless and visually lossless or lossy coding of screen content images and sequences. Particular emphasis will be placed on a combination of machine learning and statistical modeling.
Coding of Point Cloud data
Coding of point cloud geometry and attributes using deep learning tools
| Contact |
| Dat Thanh Nguyen, M.Sc. |
| E-Mail: dat.thanh.nguyen@fau.de |
| Link to person |
Point Clouds are becoming one of the most common data structures to represent 3D scenes as it enables six degrees of freedom (6DoF) viewing experience. However, a typical point cloud contains millions of 3D points and requires a huge amount of storage. Hence, efficient Point Cloud Compression (PCC) methods are just inevitable in order to bring point cloud into practical applications. Unlike 2D image/video, point clouds are sparse and irregular (see the image), which make the compression task even more difficult.
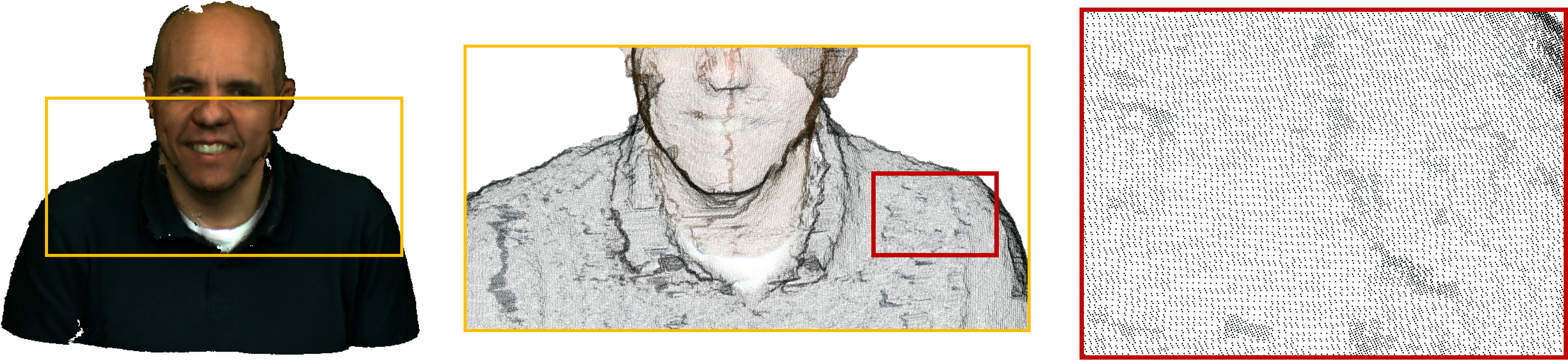
In the recent years, the research society has been paying attention on this type of data, but the compression rate is still below the compression rates of 2D-image coding algorithms (JPEG, HEVC, VVC,…). With the help of recent advances in deep learning techniques, in this project, we aim to tackle challenges in PCC including:
- Sparsity – most of the 3D space is empty, typically less than 2% of space is occupied, however, exploiting the redundancy and encoding the non-empty space are not easy tasks.
- Irregularity – unlike 2D images, where pixels are sampled uniformly over 2D planes, irregular sampling of point clouds makes it difficult to use traditional signal processing methods.
- Huge spatial volume – the information contained in a single 10 bits point cloud frame already equivalent to 1024 2D images of size 1024 × 1024. Such a point cloud would require enormous computational operations when applying any kind of signal processing technique.
Point Clouds can be encoded and then used for different purposes such as VR, world heritage, medical analysis, etc. And thus, in this project, we investigate geometry and attributes coding in both lossless and lossy scenarios to provide solutions for various applications and purposes.
2024
2023
2022
2021
2020
2019
2018
2017
2016
2015
2014
2013
2012
2011
2010
2009
2008
2007
2006
2005
2004
2002
2001
2000
1999
1998
1997
1996
1994
1993
1991