
In recent years, image processing has increasingly incorporated machine learning techniques. Deep Convolutional Networks (CNNs) have proven particularly poweful, excelling in the classification and recognition of visual content. One of the first major breakthroughs was the reliable recognition of handwritten postal codes, which marked a milestone in automated text recognition. This was followed by further significant advances, such as in facial recognition, automatic license plate detection, identification of individuals and traffic signs, as well as the detection and spatial localization of obstacles.
Intelligent image and video processing systems are now widely used beyond mobility and security applications. In the food industry, they are used for quality control, in medicine they support the early diagnosis of skin diseases and tumors. In agriculture, they enable the detection of weeds, plant diseases, and pests, contributing to more efficient use of resources. In the context of environmental and climate protection, they are used in wildfire early detection systems to help identify fires more quickly and better protect both people and nature. In the field of recycling, this technology helps to accurately and efficiently identify plastics, making their reuse and recycling more effective.
| Contact |
| Katja Kossira, M.Sc. |
| E-Mail: katja.kossira@fau.de |
| Link to person |
| PD Dr.-Ing. habil. Jürgen Seiler |
| E-Mail: juergen.seiler@fau.de |
| Link to person |
Application of Methods of Intelligent Image and Video Analysis in the Field of Recycling
The increasing relevance of the topic of environmental and climate protection affects many areas of our lives: Beaches on vacation are littered with disposable plastic bottles and there is a huge garbage swirl floating in the ocean. Temperatures are rising, yet you can hardly find anything in the supermarket that isn’t wrapped in plastic. Currently, 67% of this waste is thermally recycled, i.e. incinerated, but the efficiency of this process is merely 30%, while a lot of CO2 is emitted in the process (Source: Plastikatlas 20191). Since recycling is significantly more efficient at 85% and also emits less CO2, it is important to create efficient and inexpensive methods to classify plastics properly so that they can be reused.
To support this development, a new approach will be explored that uses intelligent image and video analysis with the aid of AI, aiming to decide which type of plastic the sample belongs to. The idea origins in the discovery of carbon chains of plastics reflecting light at different wavelengths in the infrared range to different extents, resulting in various colors for characteristic plastics. This is shown exemplary in the following figure (left: original representation, right: superimposition of images taken with filters of wavelengths 850nm, 1000nm and 1150nm).
 In order to automatically recognize plastics in the future, the camera array for multispectral imaging (CAMSI) will be further developed and adapted to the requirements. The spectral fingerprints of the different plastic classes will be determined and subsequently used to train a model. In addition, a decision matrix is created that determines the optimal filter selection based on significant peaks of the spectra. The output is then used for an unambiguous classification and the recyclable material can be fed into the recycling process. The new method is to be used, for example, in deposit machines or at sorting facilities of recycling centers.
In order to automatically recognize plastics in the future, the camera array for multispectral imaging (CAMSI) will be further developed and adapted to the requirements. The spectral fingerprints of the different plastic classes will be determined and subsequently used to train a model. In addition, a decision matrix is created that determines the optimal filter selection based on significant peaks of the spectra. The output is then used for an unambiguous classification and the recyclable material can be fed into the recycling process. The new method is to be used, for example, in deposit machines or at sorting facilities of recycling centers.
In October 2024, this research was awarded the FAU Sustainability Award (more information).
1 https://www.bund.net/fileadmin/user_upload_bund/publikationen/chemie/chemie_plastikatlas_2019.pdf
Point Cloud Upsampling Using Sparse Frequency Models
| Contact |
| Marina Ritthaler, M.Sc. |
| E-Mail: marina.ritthaler@fau.de |
| Link to person |
| PD Dr.-Ing. habil. Jürgen Seiler |
| E-Mail: juergen.seiler@fau.de |
| Link to person |
With increased availability of 3D sensors like LiDAR, three-dimensional data is often represented as point clouds. Point clouds are composed of unordered single points in a three-dimensional space. Additional to their cartesian coordinates, they can have attributes. These attributes might be colour, motion vectors, texture, reflectance, or any other information. Acquiring high resolution point clouds is expensive. Therefore, they are often sparse, noisy, and non-uniform. The task of upsampling is thus to generate a dense, complete and uniform point cloud.
In our approach, we want to increase the resolution by using the frequency selective principle. Hereby, we use the assumption of a sparse frequency domain that can be represented in terms of weighted basis functions.
Predictive Maintenance for Distributed Systems
| Contact |
| Felix Deichsel, M.Sc. |
| E-Mail: felix.deichsel@fau.de |
| Link to person |
| PD Dr.-Ing. habil. Jürgen Seiler |
| E-Mail: juergen.seiler@fau.de |
| Link to person |
In the context of Industry 4.0, predictive maintenance refers to the continuous acquisition and analysis of measurement and sensor data in order to predict the condition of machines and to plan maintenance activities in a demand-driven and proactive manner. This approach helps to reduce unplanned downtime, increase operational efficiency, and extend the service life of machines, resulting in both economic and environmental benefits.
At present, the industrial application of predictive maintenance is largely limited to the monitoring of individual machines. In contrast, the project “Learning Predictive Maintenance for Networked Device Fleets” aims to develop a fleet-wide predictive maintenance system. The objective is to determine the maintenance requirements of individual machines with higher accuracy by jointly analyzing data from all devices connected within a fleet.
To this end, various methods from machine learning and artificial intelligence are employed. The focus of the research lies in particular on anomaly detection for the early identification of deviations in machine behavior, as well as on federated learning, which enables the training of a shared, high-performance model across multiple devices without the need to centrally aggregate sensitive operational data.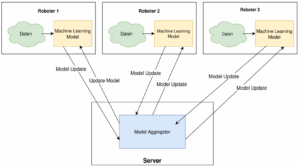
Embedded Perception for Autonomous Vehicles
| Contact |
| Maximiliane Gruber, M. Sc. |
| E-Mail: maximiliane.gruber@fau.de |
| Link to person |
| PD Dr.-Ing. habil. Jürgen Seiler |
| E-Mail: juergen.seiler@fau.de |
| Link to person |
The primary goal of Embedded Perception is to develop a data-driven framework that enables object recognition in road data, thereby facilitating the advancement of autonomous driving vehicles. The hardware system comprises multiple cameras and LiDAR sensors, while the software system consists of both an offline and an online perception component. The online component is designed to deliver real-time and precise results, effectively utilizing the limited computing resources onboard. On the other hand, the offline component operates independently on the same data once the recordings are complete, benefiting from more extensive compute resources and enabling the execution of highly complex algorithms. As a result, the outcomes are expected to be more dependable. Such a system can be utilized to generate extensive reference datasets encompassing diverse traffic and weather conditions.
The development of the Embedded Perception Framework poses several signal processing challenges, including sensor calibration, data compression, multi-modal data analysis and fusion, data augmentation, and the development of perception algorithms, among others. The key areas of our research can be broadly divided into:
- LiDAR-Camera Self-Calibration To address the requirements of a diverse operating domain and avoid heuristically tuned algorithms, we propose a self-calibration pipeline based on deep learning. This pipeline aims to perform simultaneous intrinsic calibration of the camera sensor and extrinsic calibration of the LiDAR camera setup.
- LiDAR Point Cloud Compression Efficient compression algorithms are crucial for handling the substantial data produced by LiDAR sensors, during storage and transmission. Apart from reducing memory and storage costs, smaller file sizes facilitate faster information exchange between autonomous vehicles, thereby decreasing the overall latency of the perception system. Given that these signals primarily serve downstream perception tasks like object detection, our research goes beyond traditional quality metrics like PSNR, and we develop compression algorithms that also consider their impact on detection accuracy in state-of-the-art perception algorithms.
|
Fig. 1: Demonstrator setup consisting of stereo camera and LiDAR sensor.
|
Fig. 2: Performance improvement by our methods for learning image distortions in JPEG2000 coded images.
|
 |
 |
- Learning Image Distortions for Domain Adaptation Since data-driven methods learn a particular task from annotated data samples, such methods heavily depend on the quality of the training data. That is, the training data must sufficiently resemble the data encountered during application and testing. In practice, however, unknown distortion can lead to a domain gap between training and test data, impeding the performance of a machine vision system. Examples of such unknown distortions that occur in image data are blur, noise, and coding. These distortions differ for example for different camera systems. Fig. 2a illustrates an example of the drop in performance for JPEG2000-encoded test data if the training data did not contain such distortions. To address the performance drop of image processing systems in such cases, we explore methods for learning the above mentioned unknown image distortions. The learned image distortions are then emulated on clean data, which serve as additional training data to improve the performance of image processing systems. In our work, we consider machine vision systems as a black box and develop general methods that can be used for various tasks. This approach is also called pixel-level domain adaptation. Fig. 2b shows the improvement in object detection, when using our method.
- Road Lane Detection Road Lane detection is a critical component for ensuring the safe navigation of autonomous vehicles. Our research focuses on developing a neural network-based model that leverages fused features from LiDAR and monocular camera signals to generate a 3D profile of the road. The lane detection capabilities of our model exhibit robustness to road slopes and provide accurate depth estimation.
- Object Detection and Object Tracking Object detection involves identifying and localizing road users and road signs within a captured frame from the vehicle’s sensors. Object tracking enhances perception by associating identical objects across frames, enabling motion estimation for dynamic entities like pedestrians and vehicles. In the task of 3D multi-object tracking, two approaches are commonly used. The first approach employs an end-to-end trainable object tracking system for a sequence of frames. The second approach involves using a 3D object detector for each frame individually, followed by association using a Kalman filter and the Hungarian algorithm. Our research investigates both approaches and further optimizes them to address the challenges of speed and accuracy in our online and offline processing pipelines.
| Contact |
| PD Dr.-Ing. habil. Jürgen Seiler |
| E-Mail: juergen.seiler@fau.de |
| Link to Person |
Artificial intelligence for quality assurance in industrial manufacturing
The growing amount of automation influences every aspect of our daily live. A topic that is very strongly affected by this transformation is industrial manufacturing. Modern production lines already run nearly without any human action. Due to the upcoming changes that come with Industry 4.0 this phenomenon will be even more reinforced. In order to guarantee the quality of the items produced in that manner, a final visual quality control has to be conducted. Up to now, this is still often done manually. As this is a tiring, monotonous and exhausting labour, automated solutions are searched for this problem as well.
Since some years, there are several automated optical inspection systems. Up to now, those systems use classical image processing techniques. Those techniques require a strict calibration and adjustment of the tolerance ranges and test criteria for the current item before the inspection can start. Especially in the context of Industry 4.0 with often changing inspection tasks and small batch series this is becoming very inefficient. As an alternative, a new approach is developed that uses Machine Learning techniques to assess whether an item is erroneous or not. The traditional approach to solve this problem is to acquire a huge amount to images of erroneous and fault-less items in order to use these images for the training of a neural network. The problem with this approach is that first of all a sufficiently large number of items has to be produced to acquire images of them. Another restriction is that enough erroneous items have to be available to guarantee a reliable training.

Especially in terms of a fast adaption of the production and the fabrication of individual items, this approach is not suited well. In order to eliminate the production and following assessment of items for the generation of training data for the neural network another approach is followed here. Here the training data is not acquired by a camera, but generated by a model. Therefore, images of the item that will be produced are generated based on a model of this item. The neural network is trained on these model-generated images and afterwards applied to the real acquired images of the item that is to be inspected. By this a separation into good and erroneous items can be performed.
Spectral reconstruction
| Contact |
| PD Dr.-Ing. habil. Jürgen Seiler |
| E-Mail: juergen.seiler@fau.de |
| Link to Person |
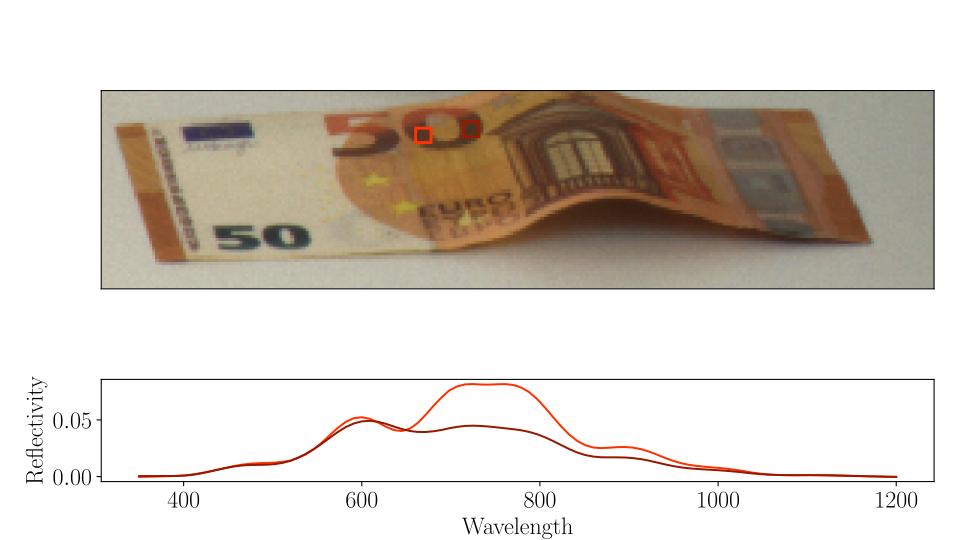
Using multi- or hyperspectral imaging system, as shown above, leads to further tasks. For a lot of applications, the reflectance spectra are an essential part for classification tasks. Therefore, reconstructing the emitted spectrum from multispectral images is a fundamental operation. This operation leads to several challenges. First of all, one typically estimates more variables than observations, which emphasizes the need for prior information. Furthermore, multispectral videos, e.g., imagine a drone flying over agricultural fields while measuring the plant health, are usually heavily affected by noise due to the limited exposure time of each frame. Consequently, spectral reconstruction techniques, which are robust to noise, need to be developed. The applications of such a technique vary heavily. For example, different types of plastic can be discriminated, drug counterfeits can be detected, or security features of bills can be examined:
| Reconstructed spectra (the colors of markers and spectra match) | Reconstructed images at specific wavelengths |
 |
 |